快速迭代,持续交付是互联网和微服务开发的核心理念。 这需要大量完善的基础设施的支撑。 对支付系统开发来说,这些基础设施尤为重要。近年来随着互联网公司在金融领域上的发力,竞争越来越激烈,新产品推出速度也在加快,而对安全的要求却是越来越高,不断的有系统或者业务的安全问题爆发。如何在快速完成业务支持任务的同时,保证开发质量,是支付系统开发面临的难题。 微服务架构是解决这个问题的利器,不过也需要强大的基础设施的支持。 “没有金刚钻别揽瓷器活”, 基础设施不完善,会反而影响微服务的开发实施效率。
微服务和自动化
传统的软件过程一个大问题是各个阶段都需要人工干预。 而微服务架构的引入,其思想是通过降低系统的复杂度来使得过程的自动化成为可能。对此,Martin Fowler首先提出了在极限编程(敏捷)中使用持续集成的观点。在微服务架构之后,由提出了持续交付的概念。 微服务架构如何支撑这些过程,可以参考相关资料,本文不再详细介绍。 而从支付系统的角度,它的基础设施建设有什么不同之处?如果从微服务的角度来考察,和其它业务系统开发并无不同之处。无非是要求更严格罢了。构建的原则也是.”人管代码,代码管机器。通过流程自动化,逐步消除软件过程中的人工干预,加快迭代,提升质量。
怎么度量支付系统基础设施建设的成熟度?我们没法从部署了多少个软件,使用了多少台机器这样硬性指标来考察。敏捷开发的一些最新理念可以帮助我们定性地度量这个进度。 软件开发过程包括编码,构建,集成,测试,交付(预发布),部署。我们可以从这流程的自动化程度来度量基础设施建设的阶段。
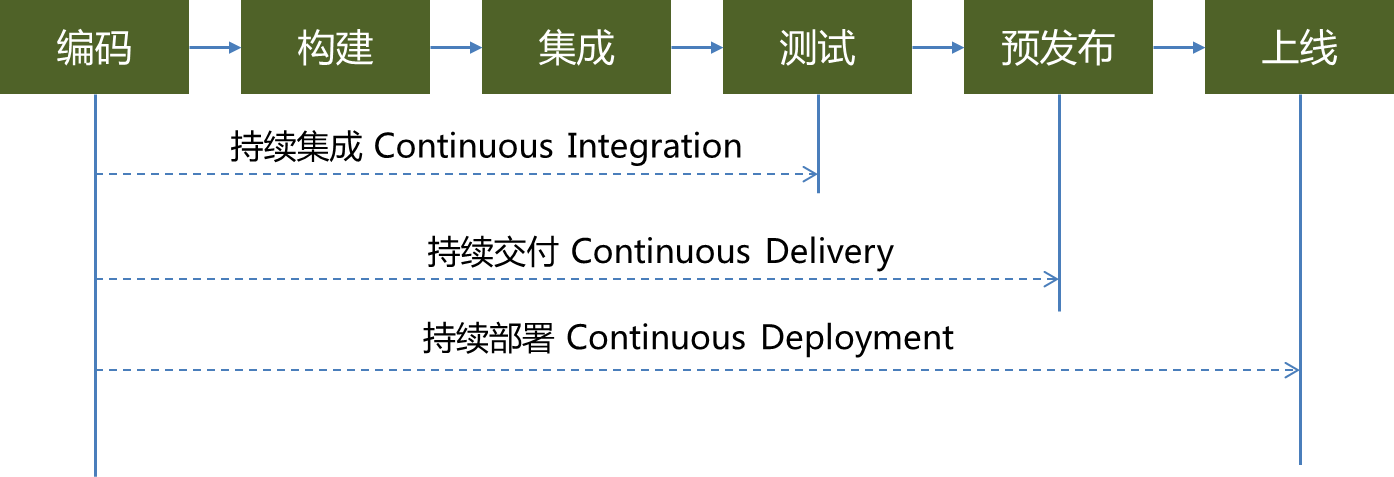
持续集成、持续交付和持续部署,分别对应自动化软件过程的三个阶段。持续集成实现了编译、发布、集成编译的自动化,并最终自动部署到集成测试环境。在测试完成后,需要人工验证和上线。 而持续交付则更进一步,在实现自动测试基础上,能够实现自动部署到预发布环境。在准线上环境确认达到可以上线的要求后,人工部署到线上环境。 持续部署是自动化的最终目标,开发完成后,能够自动地完成验证并实施到线上的系统。
不管是哪个阶段,都需要自动化的基础设施的支持。这里分头介绍其中主要的基础设施软件,以及他们的选型。
版本控制
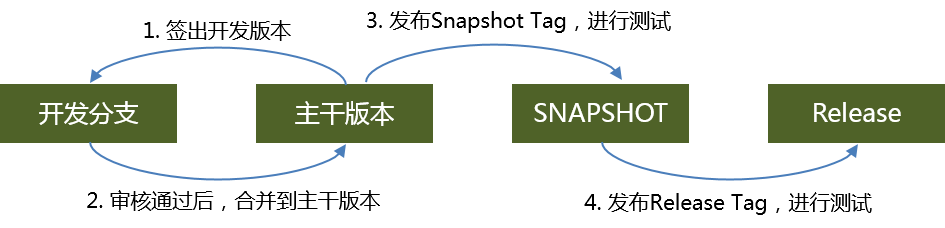
版本控制所有自动化工作的基础。国内大部分公司已经完成了从subversion到git的改造,git也成为版本控制的标配了。支付系统在版本控制上和其他系统并无太多的差异。这里需要介绍的是针对微服务架构的版本控制。 我们知道对版本控制来说,代码合并是一个很难避免的噩梦。 而微服务化可以很好的解决这个问题,由于服务的粒度小,每次变更一个人就可以搞定。每个服务有都可以独立上线,避免修改冲突。 这样版本控制就相对来说比较简单:
代码审核
支付系统的每一行代码都要执行审核!代码审核对支付来说意义重大,是避免恶意代码不可缺少的一个环节。 一般来说,支付代码要求至少是2人审核通过。代码需要执行日常审核,而不是到快发布时的统一审核。审核的工具一般是需要和版本控制相集成的。 subversion上用reviewboard, git上用gerrit或者gitlab。虽然说gitlab是比较新的系统,不过还是推荐gerrit,可以强制代码审核以及控制代码审核流程,确保两个人都OK后才能入库。
对于使用gitlab的系统而言,它的优势在于可扩展性强。gitlab默认不支持强制代码评审。但如果不强制执行代码评审,那会出现开发人员未经code view就提交自己merge代码。而reviewer 未能够及时review代码,也会影响进度。此外,开发人员没有执行代码审计(sonar)就提交代码,也是常见的事情。 好在gitlab有非常好的可扩展性,通过webhook可以根据需要实现各种额外功能。 webhook是gitlab的一个扩展点,通过用户提供的回调HTTP请求来监听git的push、comments、merge等事件。比如可以要求必须至少两个LGFM(LooksGoodForMe)才可以merge。通过webhook来监听comments,汇总两个LGFM之后,自动将代码merge到trunk上。
代码审计
或者说是静态代码审查。Apache PMD, FindBugs都是常用的工具,推荐用Codehaus Sonar系统,即可以实现和Maven的集成,也可以有Web UI可以查看代码质量。提供的审核规则也比较全面,并且可以根据公司的需求来定制。
日志搜集与分析
开发同学不碰线上系统,这是支付系统的原则。那线上系统出问题了怎么办?开发人员总是依赖日志来排查问题,一个日志汇总系统是支付平台必备的基础设施。考虑到日志最终都需要归并到一个日志仓库中,这个仓库可以有很多用途,特别是日常维护中的日志查询工作。多数指标可以在日志上完成计算的。 借助这个系统,也可以完成监控:
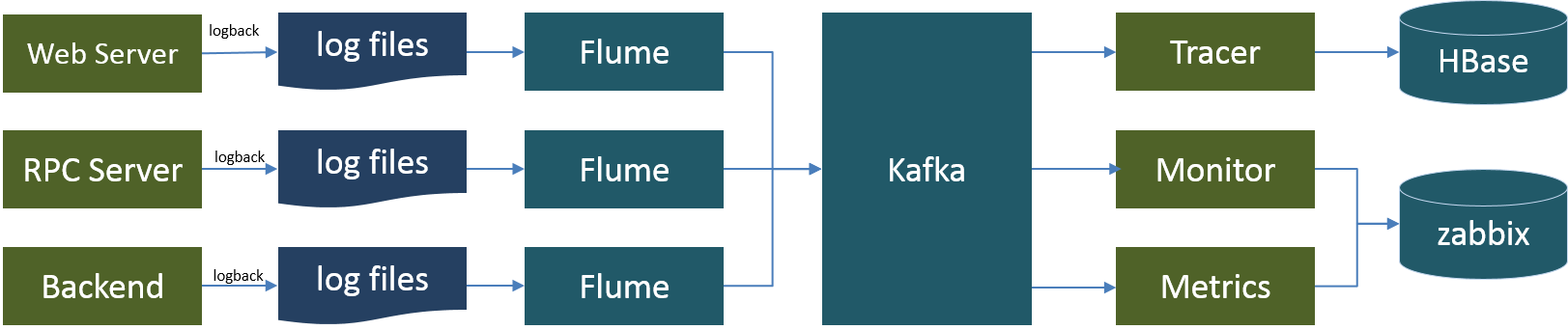
日志通过Apache Flume来收集,通过Apache Kafka来汇总,一般最后日志都归档到Elastic中。 统计分析工作也可以基于Elastic来做,但这个不推荐。 使用Apache Spark 的 Streaming组件来接入Apache Kafka 完成监控指标的提取和计算,将结果推送到Zabbix服务器上,就可以实现可扩展的监控。 Apache Flume和Logstash都可以用于日志收集,从实际使用来看,两者在性能上并无太大差异。Flume是java系统,Logstash是ruby系统。使用中都会涉及到对系统的扩展,这就看那个语言你能hold住了。 Apache Flume和Logstash都支持日志直接入库,即写入HDFS,Elastic等,有必要中间加一层Kafka吗?太有必要了,日志直接入库,以后分析就限制于这个库里面了。接入Kafka后,对于需要日志数据的应用,可以在Kafka上做准实时数据流分析,并将结果保存到需要的数据库中。
系统监控
现在基本上 Zabbix 成为监控的标配了。 一个常规的 Zabbix 监控实现, 是在被监控的机器上部署Zabbix Agent,从日志中收集所需要的数据,分析出监控指标,发送到zabbix服务器上。
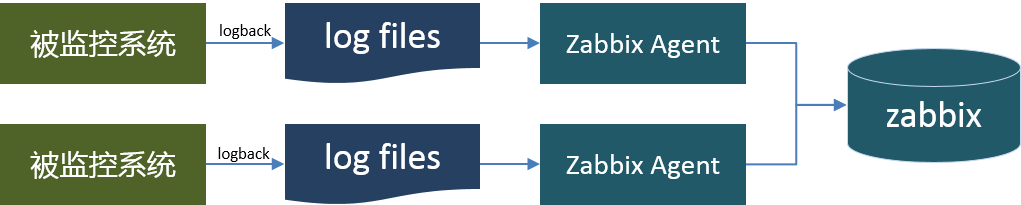 这种方式要求每个机器上部署 Zabbix 客户端,并配置数据收集脚本。Zabbix的部署可以作为必装软件随操作系统一起安装。
这种方式要求每个机器上部署 Zabbix 客户端,并配置数据收集脚本。Zabbix的部署可以作为必装软件随操作系统一起安装。
持续集成
毫无疑问,Jenkins就是CI的不二之选。 但是这也只是一个工具,怎么用还得结合业务来实现。而上面列出来的这么多工具和使用要求,如何确保开发人员安规范来实现,并且尽可能地自动化,一个解决方案就是用集成工具将这些活动串起来。这里不详细介绍Jenkins的原理或者它和hudson的恩恩怨怨,重点描述如何使用。 Jenkins使用的要点是设置各个Job。而Job的设置,又分为线上和测试的Job。测试环境的Job分为 部署、启动、停止三个群组。线上分为 预部署、部署、启动和停止四个群组。 在每个群组中,每个项目对应一个可执行Job。
在测试环境部署执行如下工作:
-
获取受控代码。如果有指定版本号,则下载该版本号对应的代码;否则获取最新的Tag分支并下载该代码。集成是必须从代码开始构建,目的是保证线上运行的系统和版本控制服务器上的代码是一致的,而不是从某人机器上修改后的代码直接传上去的。 如果出现问题,只要获取该版本的代码即可定位到出问题的地方;
-
执行代码审计
-
执行maven deploy命令,执行编译、单元测试、版本发布等工作。 注意,这个阶段发布的包,都是SNAPSHOT版本的包。
-
生成javadoc, 接口文档,发布到测试服务器上,测试人员将对这个文档做验证。
-
生成单元测试覆盖率报告、代码质量报告。
-
发布系统到测试环境上。
在线上环境部署执行如下工作:
-
如果有指定版本号,则下载该版本号对应的代码;否则获取最新的Tag分支并下载该代码;
-
执行mvn setVersion命令, 将所有SNAPSHOT版本依赖修改为正式版本依赖。
-
执行代码审计
-
执行maven deploy命令,执行编译、单元测试、版本发布等工作。 注意,这个阶段发布的包,都是RELEASE版本的包。
-
生成javadoc, 接口文档,这是正式版本的文档。
-
发布系统到线上环境上。
以上支付系统中涉及的主要的基础设施,本文仅完成初稿,后续将会逐步再完善其他的基础设置。 也欢迎大家补充完善。
修订记录
- 2016年11月12日 完成初稿
感谢您对本文的关注,如需要及时收到凤凰牌老熊的最新作品,或者有相关问题探讨,请扫码关注“凤凰牌老熊”的微信公众号,在公众号里留言或者回复,可以尽快处理,谢谢。
本文欢迎转载,转载时请注明本文来自 微信公众号“凤凰牌老熊”。
