接上一篇支付风控数据仓库建设。支付风控涉及到多方面的内容,包括反洗钱、反欺诈、客户风险等级分类管理等。 其中最核心的功能在于对实时交易进行风险评估,或者说是欺诈检测。如果这个交易的风险太高,则会执行拦截。由于反欺诈检测是在交易时实时进行的,在要求不能误拦截的同时,还有用户体验上的要求,即不能占用太多时间,一般要求风控操作必须控制在100ms以内,对于交易量大的业务,10ms甚至更低的性能要求都是必须的。 这就需要对风控模型进行合理的设计。一般来说,要提升风控的拦截效率,就需要考虑更多的维度,但这也会带来计算性能的下降。在效率和性能之间需要进行平衡。
本文重在介绍建立风控模型的方法,每个公司应该根据自己的实际业务情况和开发能力来选择合适的模型。这里列出来的模型仅为了说明问题,提供参考。
一、风险等级
做风控拦截,首先要回答的问题是风险等级怎么划分? 目前主流的风险等级划分有三种方式, 三等级、四等级、五等级。
- 三等级的风险分为 低风险、中风险和高风险。 大部分交易是低风险的,不需要拦截直接放行。 中风险的交易是需要进行增强验证,确认是本人操作后放行。 高风险的交易则直接拦截。
- 四风险等级,会增加一个中高风险等级。此类交易在用户完成增强验证后,还需要管理人员人工核实,核实没问题后,交易才能放行。
- 五风险等级,会增加一个中低风险等级。此类交易是先放行,但是管理人员需要进行事后核实。 如果核实有问题,通过人工方式执行退款,或者提升该用户的风险等级。
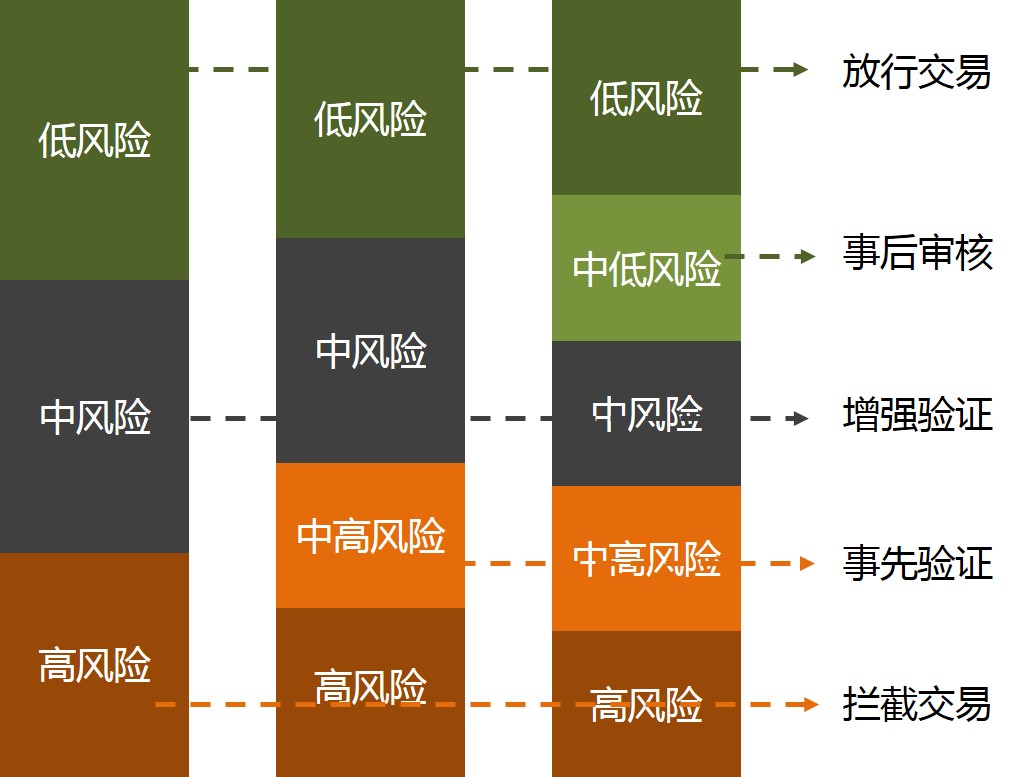
大部分支付系统是使用三等级的风险。
二、基于规则的风控
规则是最常用的,也是相对来说比较容易上手的风控模型。从现实情况中总结出一些经验,结合名单数据,制定风控规则,简单,有效。 常见的规则有:
1. 名单规则
使用白名单或者黑名单来设置规则。具体名单如上文所述,包括用户ID、IP地址、设备ID、地区、公检法协查等。
比如:
- 用户ID是在风控黑名单中。
- 用户身份证号在反洗钱黑名单中。
- 用户身份证号在公检法协查名单中。
- 用户所使用的手机号在羊毛号名单列表中。
- 转账用户所在地区是联合国反洗钱风险警示地区。
2. 操作规则
对支付、提现、充值的频率按照用户账号、IP、设备等进行限制,一旦超出阈值,则提升风控等级。
- 频率需综合考虑(五)分钟、(一)小时、(一)天、(一)周等维度的数据。由于一般计算频率是按照自然时间段来进行的,所以如果用户的操作是跨时间段的,则会出现频率限制失效的情况。 当然,比较复杂的可以用滑窗来做。
- 对不同的风险等级设置不同的阈值。 比如:
- 用户提现频次5分钟不能超过2次, 一小时不能超过5次,一天不能超过10次。
- 用户提现额度一天不能超过1万。
- 用户支付频次5分钟不能超过2次,一小时不能超过10次,一天不能超过100次。
3. 业务规则
和特定各业务相关的一些规则,比如:
- 同一个人绑定银行卡张数超过10张。
- 同一张银行卡被超过5个人绑定。
- 同一个手机号被5个人绑定。
- 一个周内手机号变更超过4次。
- 同一个对私银行卡接受转账次数一分钟超过5次。
4. 行为异常
用户行为和以前的表现不一致,比如:
- 用户支付地点与常用登录地点不一致
- 用户支付使用个IP与常用IP地址不一致
- 用户在短时间内,上一次支付的地址和本次支付的地址距离非常远。 比如2分钟前在中国支付的,2分钟后跑到美国去支付了。
5. 风控拦截历史规则
用户在某个业务上的消费行为被风控网关多次拦截。
规则引擎优点:
- 性能高: 对订单按照规则进行匹配,输出结果。一般不会涉及到复杂的计算。
- 易于理解和分析: 交易被拦截到底是触犯了那条规则,很容易输出。
- 开发相对简单。
规则引擎存在的问题:
- 一刀切,容易被薅羊毛的人嗅探到。比如规则规定超过5000元就进行拦截,那羊毛号会把订单拆分成4999元来做。 一天限制10笔,那就薅到9笔就停手了。
- 规则冲突问题。当一笔交易命中IP白名单和额度黑名单的时候应该如何处理?
规则引擎看起来简单,但也是最实用的一类模型。 它是其它风控模型的基础。实践中,首先使用已知的规则来发现存在问题的交易,人工识别交易的风险等级后,把这些交易作为其它有监督学习的训练数据集。
三、决策树模型
风险评估从本质上来说是一个数据分类问题。 和传统的金融行业风险评估不一样的地方,在于数据规模大、业务变化快、实时要求高。一旦有漏洞被发现,会对公司造成巨大损失。 而机器学习是解决这些问题的利器。 互联网金融风控离不开机器学习,特别是支付风控。 在各种支付风控模型中,决策树模式是相对比较简单易用的模型。
如下的决策树模型,我们根据已有的数据,分析数据特征,构建出一颗决策树。当有一笔交易发生时,我们使用决策树来判断这笔交易是否是高风险交易。
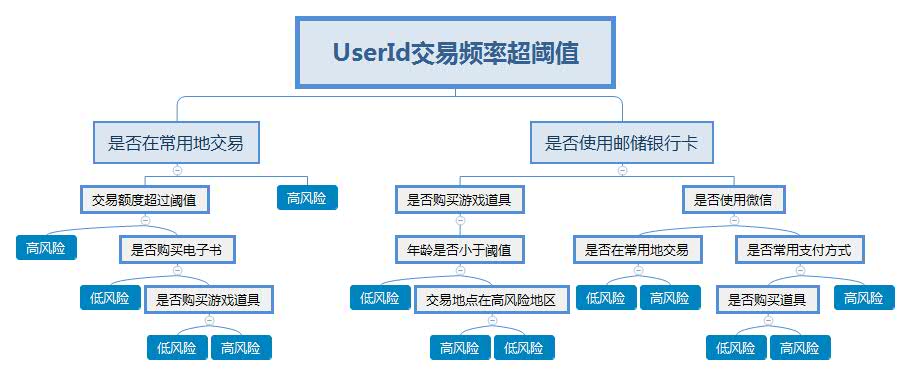 这种模型的优点是非常容易理解,检测速度快。 因而也是现有机构中常用的模型之一。 风控模型存在的主要问题是其产生的结果比较粗略。同样的两个交易被判定为高风险,究竟哪种交易风险更高,决策树模型无法给出答案。
这种模型的优点是非常容易理解,检测速度快。 因而也是现有机构中常用的模型之一。 风控模型存在的主要问题是其产生的结果比较粗略。同样的两个交易被判定为高风险,究竟哪种交易风险更高,决策树模型无法给出答案。
四、评分模型
比决策树模型更进一步,现在也有不少公司在使用评分(卡)模型。 银行在处理信用风险评级、反洗钱风险等级时,往往也是使用这种方法。
每个公司的模型都不一样,一个参考模型如下:
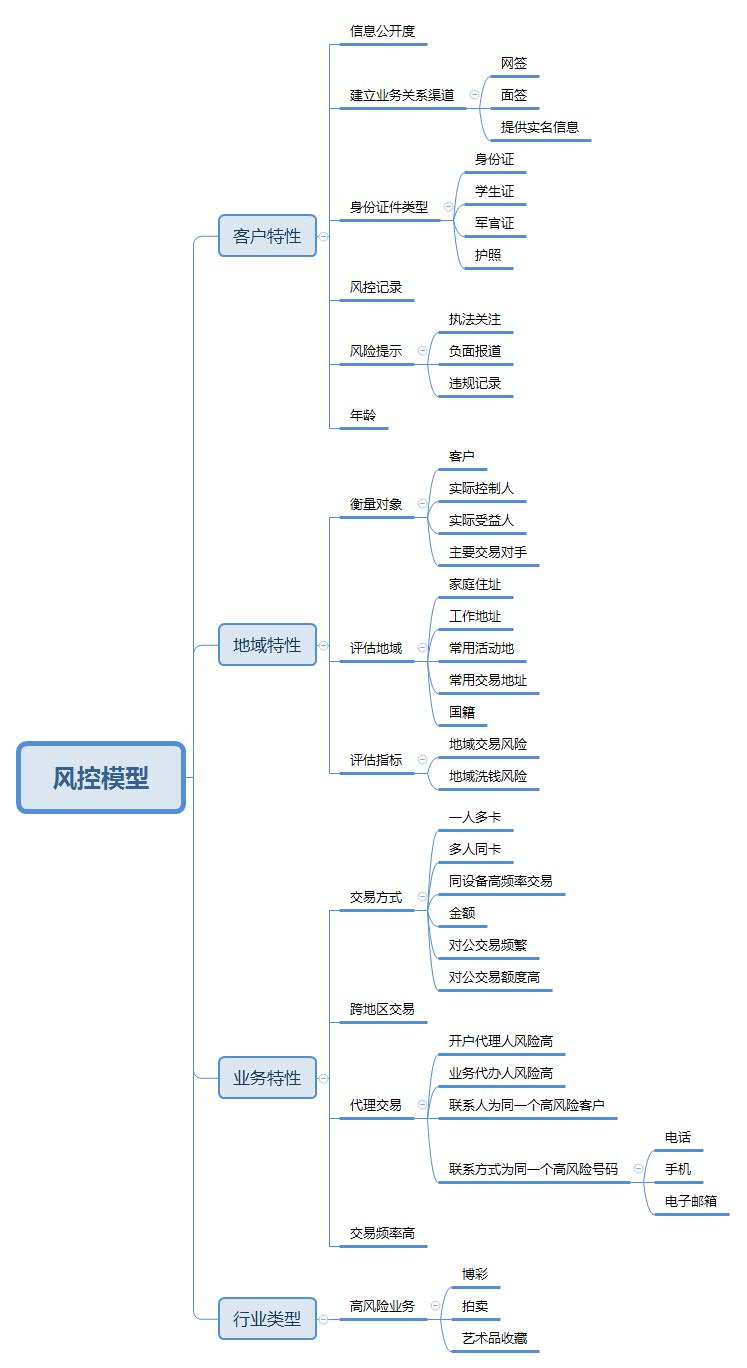
该模型为参考《金融机构洗钱和恐怖融资风险评估及客户分类管理指引》编制,仅具参考意义。虽然银行间的评分模型有很好的参考价值,但互联网公司由于业务和数据的不同,评分模型参考价值不大。
每个公司需根据自己的业务情况来制定评分模型,之后为各个指标指定权重比例。 权重评分结果为0~100分的区间,之后按照区间划分,指定风险等级。比如:

当然,评分区间也需要根据企业的实际情况来制定。 评分模型的优势在于:
- 性能比较高,针对交易进行指标计算,按照区间来确定风险。
- 相对于规则,如果指标设置合理,其覆盖度高, 不容易被嗅探到漏洞。
- 理解和分析也比较容易。 如果交易被拦截了,可以根据其各项打分评估其被拦截的原因。
存在的问题:
- 模型真的很难建立。指标的选择是一个挑战。
- 各个参数的调优是一个长期的过程。
我们知道从一条交易记录中可以挖掘的关联数据有上百个,衍生数据就更多了。比如从支付地址,可以聚类出常用地址,衍生出当前地址和常用地址、上一次支付地址之间的距离,而这些指标在构建模型时都可能使用到。 所以第一个问题是,如何从这些指标中建立一个合适的模型?这就涉及到机器学习的问题了。 模型不能凭空建立,我们可以通过规则来对现有数据进行筛选和标注,确定这些记录集的风险等级。 这些数据作为样本来训练模型。可用的算法包括Apriori、FP-growth等。算法实现请参考相关文档。
在确认相关参数后,模型在使用过程中还需要不断对相关参数进行调整。这是一个拟合或者回归的算法,Logistic算法、CART算法,可以用来对参数做调优。
总之,模型的建立是一个不断学习、优化的过程。 而每一个模型的发布,还需要进行试运行,AB测试和上线。 这个过程,将在下一篇的风控架构中介绍。
五、模型评估
风控本质上是对交易记录的一个分类,所以对风控模型的评估,除了性能外,还需要评估“查全率”和“查准率”。 如下图所示:
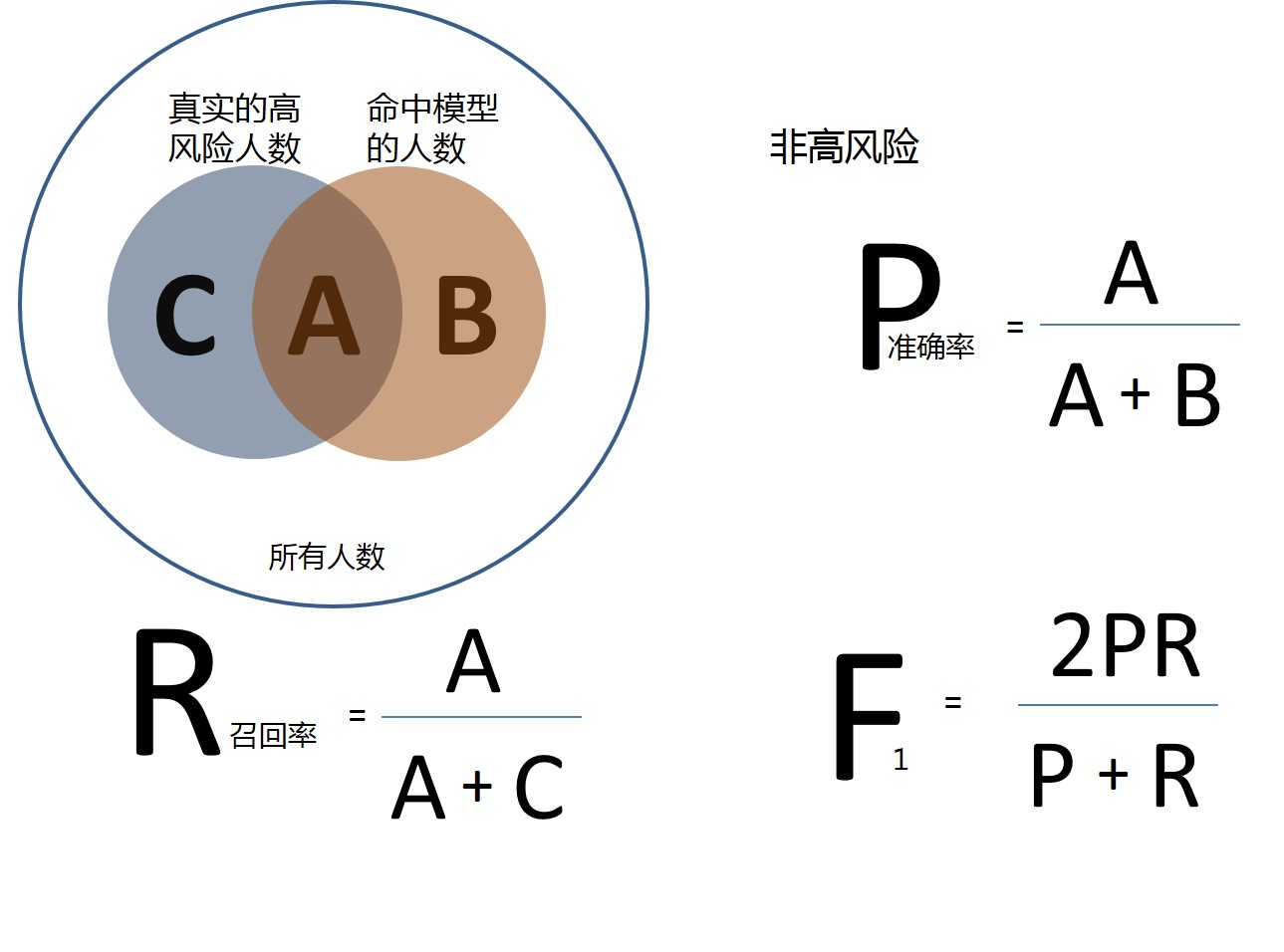
以评估高风险人群的效果为例,
- Precision, 准确率,也叫查准率,指模型发现的真实的高风险人数占模型发现的所有高风险人数的比例。
- Recall,召回率,也叫查全率,指模型发现的真实的高风险人数占全部真实的高风险人数的比例。
理想情况下,我们希望这两个指标都要高。实际上,往往是互斥的,准确率高、召回率就低,召回率低、准确率高。如果两者都低,那就是模型不靠谱了。 对于风控来说,需要在保证准确率的情况下,尽量提高召回率。 那怎么发现实际的高风险人数呢? 这就需要借助规则模型,先过滤一遍,再从中人工遴选。
从实际应用情况来看,目前国内大部分团队使用Logistic回归+评分模型来做风控,少数人使用决策树。国外的PayPal是支付平台风控的标杆,国内前海征信、蚂蚁金服等会使用到更高级的神经网络和机器学习,但实际效果未见到实证材料。
- 支付风控场景分析;
- 支付风控数据仓库建设;
- 支付风控模型和流程分析(本文);
- 支付风控系统架构
感谢您对本文的关注,如需要及时收到凤凰牌老熊的最新作品,或者有相关问题探讨,请扫码关注“凤凰牌老熊”的微信公众号,在公众号里留言或者回复,可以尽快处理,谢谢。
本文欢迎转载,转载时请注明本文来自 微信公众号“凤凰牌老熊”。
