一、 银联扫码与聚合支付
Q:现在银联的二维码和微信支付宝能聚合在一起吗? A:可以
Q:可以聚合在一起是指通过聚合支付,用户主扫这种模式?
A1:好像银联的不能和支付宝微信的聚合
A2:
- (提问者)根据我们沟通下来的结果看,目前银联二维码,用户主扫的都是根据订单信息动态生成的码,扫了之后要去银联这边查订单信息的
- 但是是能做交易,就是麻烦一点
- 第三方支付比如支付宝微信,挂在小店里的静态码一般都是只包含了商户信息,银联二维码规范里支持,但是银联好像自己没做,也没商户支持
- 不过主扫风险也是存在的,估计银联是从风险考虑的结果吧
A3:银联针对小微商户,是有静态码的, 初始限额较低(好像是500),不过可以通过完善商户信息或者根据交易频次之类的,进行调额。但银联的静态码,目前了解下来,没办法像微信、支付宝那样,聚合到一起。 商家只能贴一个微信+支付宝+xxx钱包的聚合静态码,再贴一个 银联静态码。
Q:群里有人完成过 银联静态码的聚合嘛?我目前了解到的信息 是没法聚合,但也不晓得是不是有变通的方法
A1:不行的吧,除非扫码的app支持,但是这个要一个个app谈。静态码可以是网址,但是这个网址能不能访问,怎么处理是由扫码app说了算的
A2:我们分析下来,银联的静态码,是后台接口模式,跟微信、支付宝的 前台js sdk/js api 方式 不一样,即使勉强合成一个码,在支付过程和体验上 也有很大的问题…
A3:是的,银行的APP不支持其他公司的链接的,会有类似下图的提示
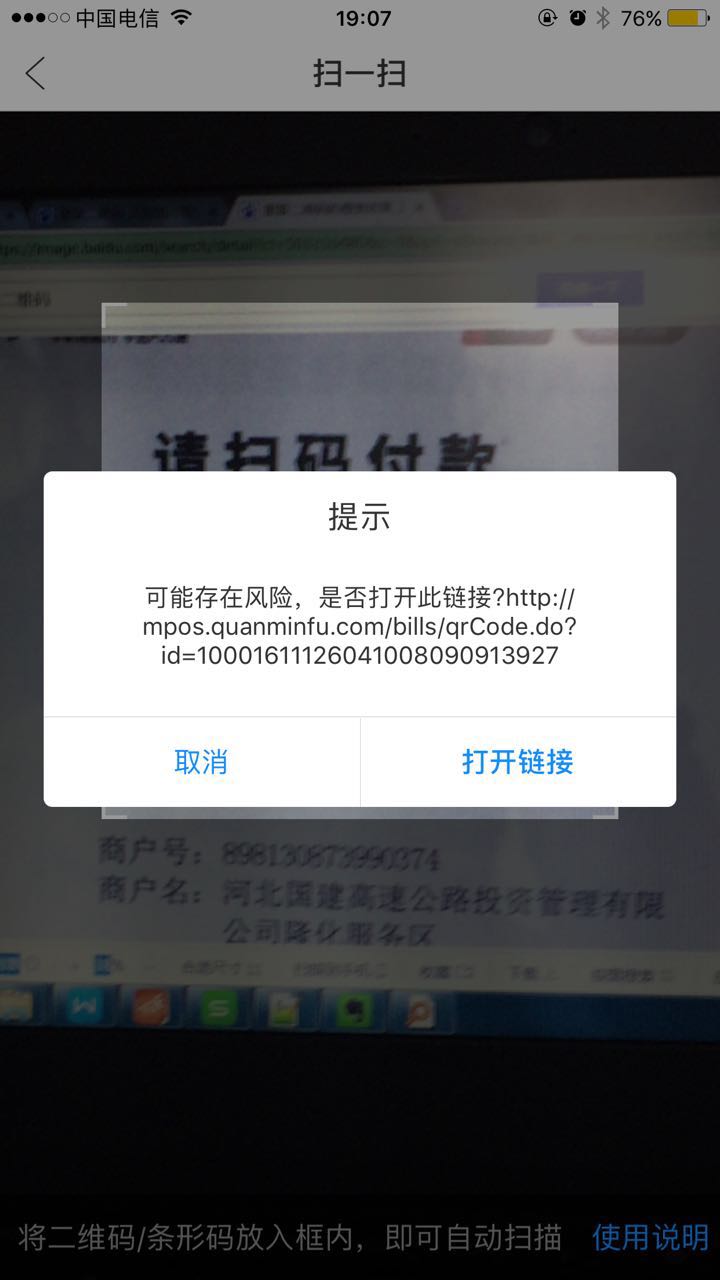
A4:银联有三套二维码系统,目前很难聚合
二、用户画像数据处理方法
Q:群里有玩客户画像的朋友吗?
A:做过用户画像
Q:你们是用的哪种数据库?SQL的还是NOSQL的?
A:sql
Q:你说的用户画像 是先做用户标签 然后看群体 特征的吗?
A:用户画像,我理解主要是行为画像,就是把一个用户的行为分类
Q:那么多的维度数据,是如何组织的?通过标签过扩展?
A:对呀,信息中心就是一个个 行为分类。标签的加工 有的也会用一下挖掘模型,流失 提升 响应 细分,后来 还加了 一些社会网络分析 研究 交易关系 静态关系
Q:那就是相当于一个KV库了?
A:可以这么说,标签和kv 感觉有点不太一样,kv 是数值吧,便签是、高 、中、低或者01
Q:用SQL能放多少数据量?
A:teradata 一张表 放 几亿条 没什么压力的,但也不推荐用td。民生信息中心习惯用td 并没有什么特别的理由,维护确实有点麻烦
Q:大宽表得有多宽?
A1:200多个字段
A2:要多宽有多宽,互联网公司 画像类存储一般用 Hbase,不会用这种商业产品
A3:我在包商 也用了hadoop那套,感觉其实 并不好用
Q:在HBASE也是建一张宽表?
A:是的
Q:用了hadoop那套,不好用在哪里?
A1:Hadoop那一套的运维成本还是较高的 要有专门的人来运维集群。一般适合整个生态配合起来用 spark hbase impala这些。hbase一般不会直接对外输出的,hbase不适合直接提供线上服务 一般上层接一个缓存
A2:我用5台cdh做集群性能不行
Q:应用系统怎么用呢?是不是查询。业务系统查询向缓存查询即可hbase中数据用于进行离线的分析
A:这个是我规划架构,和你们说的也差不多
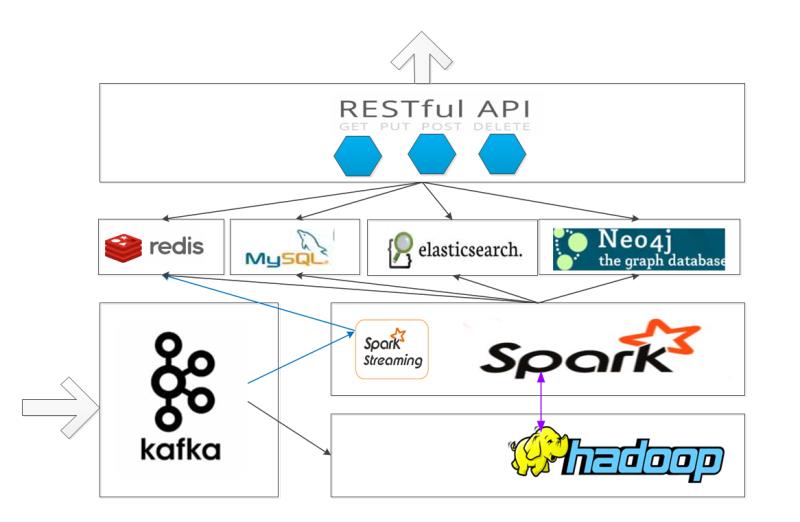
- 一部分 是查询 还有一部分 画像也是要作为 推荐系统的数据源 之一呀,差不多就是这个架构
- 性能你可以通过后台导出到关系数据库中
- 推荐系统service层也可以复用这个缓存 或者 另行缓存
Q:这是什么的架构?
A:分析系统。架构模式上,属于lambda架构
Q:没体现离线的部分,离线部分的历史数据通过什么进行上浮呢
A:不在这体现,有数据交换中心
Q:是OLAP分析吗
A:可以这么理解。
Q:但是跟用户画像好像没啥关系?
A:这个没有体现业务,有关系,涉及到如何画的问题一些确定的模型,表结构其实就是一定的
Q:我问个问题,为什么非要用一张宽表,而不用多张表?用多张表模型结构很清晰
A1:1.这是一个纯客户级的,2.不保留历史 3.标签的一般不会剧烈变化 4.标签 往往是挖掘模型的数据源 一张宽表 方便挖掘
A2:列式存储, 大宽表但是不影响性能 权限控制 标签可以独立进行更新管理,模型结构清晰 这是伪命题 你有一张表 就可能有 1w张表。
Q:以上后续如何进行维护,不保留历史 hbase可以保留历史
A:我是不太想 保留历史 空间老不够 申请扩容又不批 标签数据相对稳定 就不保留啦
Q:这个不应该是原始数据的任务吗?
A1:原始数据分散在 mysql file parquet 各种地方 , 这块首先要先管理起来 ETL 是第一步 然后是分析建模, 打标签, 存储到hbase。最后就是数据上浮到缓存 进行对外服务。简单说就是这三步,可以保留一个 只是hbase的数据结构可以让你多保留几个版本。但是一般也没人用…
A2:我的设计思路是这样的:原始数据基本上都是实时数据,所以全量到Hadoop(先不考虑如何存储),对外输出也是要求实时性高的,所以同时上送到实进计算层用Spark Streaming将结果存入到前端的存储库中(如Redis,mysql),批量计算模型则采用Hadoop中数据进行全量计算,将全量结果推入到前羰存储库中。
A3:我们是通过位的方式来保存标签,一个列能保持64个标签,每个列相当于一个组。通过多个列来支持更多标签。
Q:我想知道是所有属性都需要用标签吗?为什么不ECIF那样的思路?
A1:这样存储数据量比较小,但是运算量比较大。1000万个用户数据在MySQL上也是秒级就能搞定
Q:画像更侧重长期数据的累积 实时需求不大吧? 不同的人同一标签的权重不同
A1: 实时性的需求我就不说了,因为涉及到客户画像、用户行为画像
A2:使用位存储的方式,能够很好的支持各种标签的交集、并集、合集运算。
A3:标签 应该是比ecif的 复杂一点,偏向于营销策略 比如 经营户标签(周期性转入 转出),而且标签有比ecif 更有预测
Q:使用位存储的方式,能够很好的支持各种标签的交集、并集、合集运算。你说的是计算效率吗?
A:因为都是二进制的运算,在内存就能很快计算并且能够并行化。
Q:long型这段 一个这段只能表示64个 计算交集这些直接用数据库位运算吗?
A:使用java计算。我们当时数据量不太大,只有1000多万用户,使用单个mysql就搞定了,基于各种标签的操作基本取决于mysql的全表扫描的时间。优化一下,可以把常用的客户放在NoSQL数据库中。当时数据库方案已经能解决业务需要了,因此没有使用任何NoSQL。
Q:效率慢吧 虽然单个位很快 但是数据库要遍历每条记录 时间花在数据扫描上了 位存储并不能提升效率
A1:特定条件查询性能如何?因为涉及到模糊查询了
A2:也不一定慢,因此数据库内部存储占用的空间很小。其他的方式数据库占的存储明显大很多,查询数据库造成的数据库扫描会慢。这是一个平衡。
Q:或者倒转过来 以标签查用户 主要看场景 应用关注决定存储方式 不一定哪个好
A:对,要根据场景。没有银弹。还是要根据场景,进行相应的估算或者性能压测比较。
Q:能否分享一下用SQL库的理由,使用过程中有没有什么坑?我的一个感觉就是全用标签,数据关系比较乱,不容易管理 A:是民生信息中心 习惯用td 并没有 什么特别的理由。做成一个大宽表
三、其他
Q:用户积分兑换和用户等级权益设计,谁能给点思路,有点不解,谢谢!
A:参考国内最优秀的积分体系和等级体系 QQ会员
Q:咨询下各位,银联云闪付线上和线下收取的服务费价格是否一致?还是区别定价的? ==待回复==
本文档来自支付产品技术交流群的聊天记录整理,由志愿者整理并发布到本网站。如需要及时收到来自支付产品技术交流群的最新消息,请扫码关注“凤凰牌老熊”的微信公众号。 本群面向支付行业的有经验(2年以上)的产品经理、软件工程师、架构师等,提供交流平台。如想加入本群,请在本文评论中留言(不公开),说明所在的公司、负责的工作、入群分享的主题和时间。
- 长按或者扫描二维码来打赏,感谢支持群管理工作!

- 请扫码关注“凤凰牌老熊”的微信公众号。
